
Artítculo publicado originalmente en el blog «Piensa en software, desarrolla en colores» de ENCAMINA.
Como seguro os habréis dado cuenta, últimamente estoy implementando muchísimos proyectos «muy chulísimos» (😅) con las librerías del Semantic Kernel, un marco de trabajo de código abierto (open source) que principalmente se enfoca en facilitar la combinación de mensajes e indicaciones – los famosos prompts – para Inteligencias Artificiales generativas basadas en las tecnologías de OpenAI.
Y ahí hay un punto importante y es que, en su estado actual, Semantic Kernel por ahora sólo opera únicamente con OpenAI, ya sea la variante de Azure o la propia de OpenAI.
Pero… ¿y si queremos usar un modelo que no sea de OpenAI con Semantic Kernel? ¿Si queremos usar recursos de otro proveedor de Inteligencia Artificial?
¡Quédate conmigo que te explico cómo podemos integrar modelos de otros LLMs (Large Language Models) como los disponibles en Hugging Face en nuestros proyectos de IA usando Funciones Nativas y plugins de Semantic Kernel!
El código fuente de este artículo lo podéis conseguir en GitHub, aquí 👉🏻 https://github.com/rliberoff/BLOG-001-Semantic-Kernel-Native-Functions.
Creando una Función Nativa para la integración con otro LLM
En Semantic Kernel, las Funciones Nativas son básicamente código en nuestro lenguaje de programación de elección, en mi caso C#.
Para crear una Función Nativa, primero debemos definir un plugin. Esto es algo súper sencillo, básicamente es crear un directorio dentro de nuestro proyecto en el cual dejaremos clases que representarán a nuestros plugins con métodos que representarán a nuestras funciones.
En nuestro caso, vamos a realizar una integración con «roberta-base-squad2» disponible en Hugging Face. Este modelo nos permite integrarnos con un LLM llamado RoBERTa (nombre gracioso para Robustly Optimized BERT Approach) desarrollado por la empresa deepset (los mismos de Haystack).
El modelo «roberta-base-squad2» nos permitirá realizar preguntas que serán contestadas a partir del contenido de un contexto que también debemos suministrar. El resultado retornado nos dará la respuesta junto con un valor numérico que indicará el índice de confiabilidad de la calidad de dicha respuesta, es decir, un score cuyo valor cuánto más alto sea indicará que la respuesta es de mejor calidad y, por el contrario, cuanto más bajo sea que la respuesta es menos confiable.
Para esta integración es fundamental que tengas una cuenta en Hugging Face, ya que necesitarás un token para autenticarte al realizar las llamadas al API REST que nos da conectividad con el modelo de «roberta-base-squad2». Perfectamente te valdrá una cuenta gratuita para esto 😏
Para gestionar el token de Hugging Face crearemos una clase de opciones llamada HuggingFaceOptions con una propiedad Token que inicializaremos con un valor que obtendremos del fichero de configuración (appsetttings.json).

Recordemos que las clases de opciones las configuramos con inyección de dependencias en el archivo Program.cs:

Con esta parte de la carpintería básica ya montada, el siguiente paso será crear el directorio Plugins (no somos muy originales con los nombres 😅) y dentro de éste crearemos una clase llamada HuggingFaceDeepsetRobertaQuestionsAnsweringPlugin (de nuevo los nombres no son mi fuerte 😅). Esta clase representa al plugin que nos dará conectividad con el modelo, y cada uno de sus métodos públicos serán las Funciones Nativas que podemos utilizar con Semantic Kernel.
En nuestro caso sólo tendremos un método llamado AskQuestionWithContextAsync para integrarnos al modelo «roberta-base-squad2». Este método toma dos variables: el contexto y la pregunta, las cuales son usadas para armar la llamada al modelo «roberta-base-squad2» mediante un API REST de Hugging Face (líneas 30 a 37).
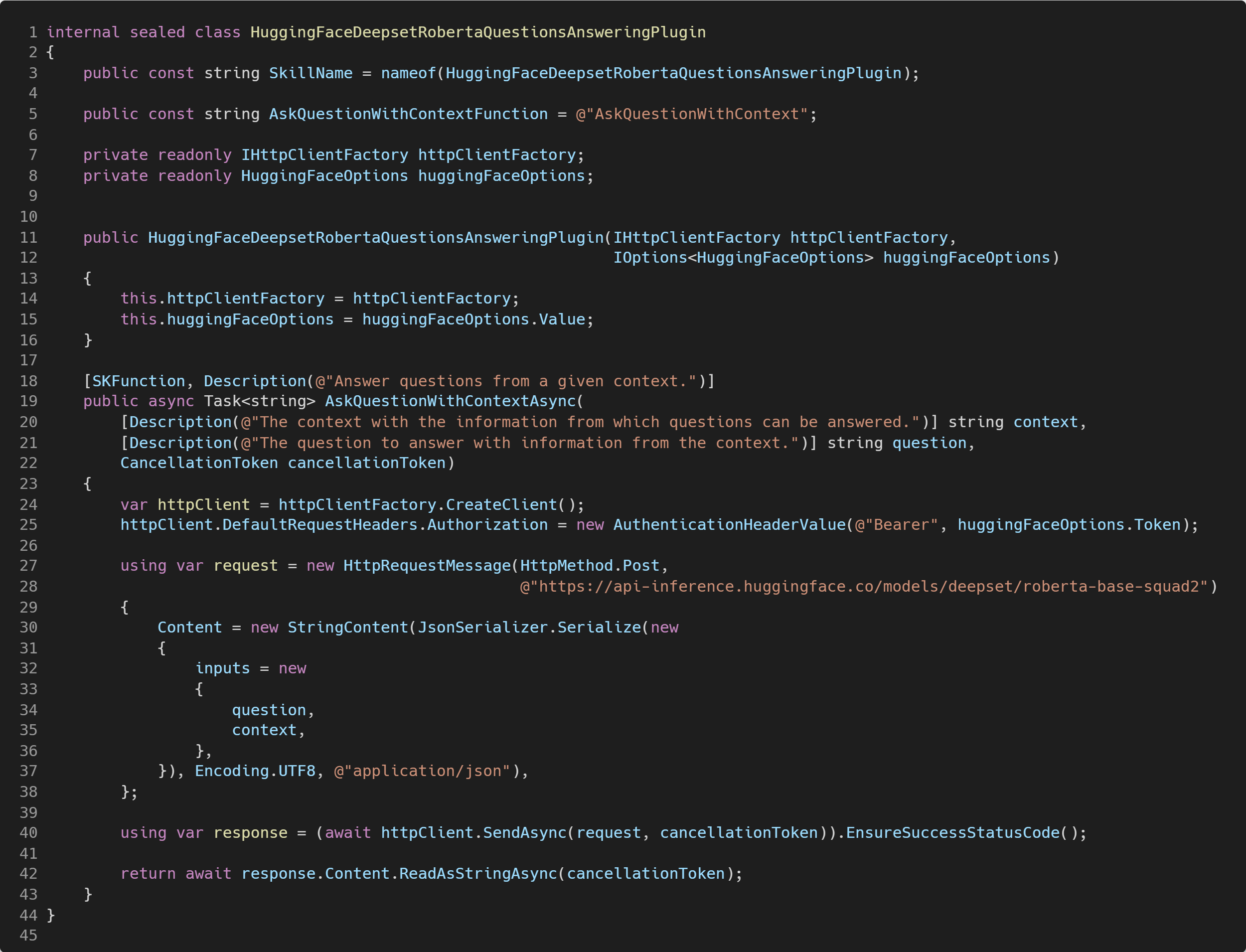
Un detalle importante con las funciones en Semantic Kernel (sean Nativas o Semánticas) es que todo se gestiona con strings. Esto quiere decir que lo que retorne nuestra Función Nativa (el método AskQuestionWithContextAsync) sólo puede ser un string. La parte interesante, es que podemos devolver un JSON como string que después podemos parsear para crear un objeto más concreto y específico. Por esa razón es que, como ves en el código, se retorna directamente el contenido de la respuesta recibida de la llamada al API REST.
Y como puedes apreciar, ¡no hay magia! La integración con otros LLMs en Semantic Kernel la podemos hacer de formas tan pueriles o triviales como llamadas a un API REST, o integrarnos con un SDK que puedan ofrecernos a través de paquetes tales como los NuGet.
Ahora tenemos que configurar Semantic Kernel para que pueda hacer uso de nuestra Función Nativa.
Configurando Semantic Kernel con la Función Nativa
Configurar el Semantic Kernel en nuestros proyectos es realmente sencillo. Todo se hace (habitualmente) en el Program.cs.
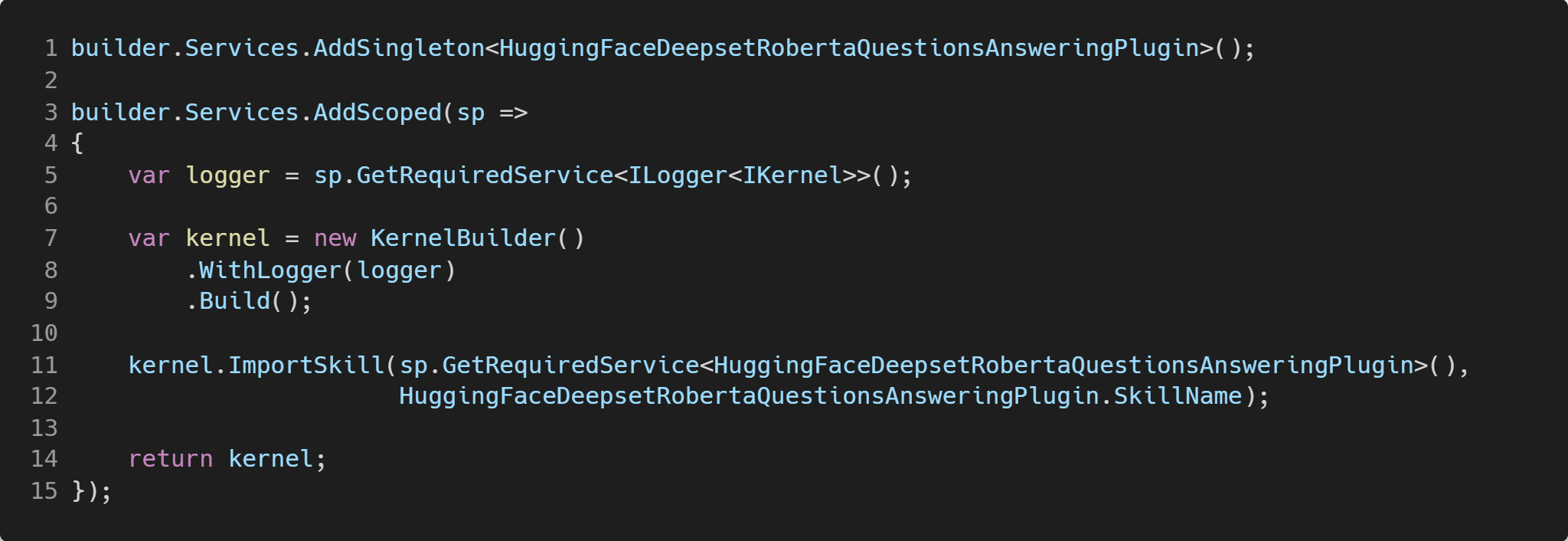
Nuestra Función Semántica la hemos codificado para que perfectamente pueda ser registrada en el contenedor de dependencias de .NET como un singleton, lo cual nos ayudará ligueramente con el desempeño del código.
Al configurar una instancia de Semantic Kernel, es recomendable para escenarios web que se registre como Scoped, ya que internamente el Semantic Kernel gestiona estados y contextos que en escenarios compartidos (usualmente web) podrían producir efectos secundarios y comportamientos inesperados no deseados si se registra como Singleton. También recuerda que es siempre una buena idea configurar un logger con el Semantic Kernel, pues así podrás saber qué ha podido salir mal en caso de errores; a mí, particularmente me gusta usar Azure Application Insights como servicio para mis trazas y registros de eventos, y podrás ver cómo lo he configurado en el código del Program.cs disponible en el repo de GitHub.
Dentro de la configuración, una vez que tenemos un kernel establecido, importamos la Función Nativa (líneas 11 y 12) proporcionando una instancia de ésta y un nombre para la skill que representa.
No es nuestro caso, pero puede ocurrir que tengas Funciones Nativas complejas, con inicializaciones complicadas o costosas en términos de recursos. Si eso ocurre, mi recomendación es que inviertas cierto tiempo y esfuerzo en implementar un patrón Factory para la skill, y que pases una instancia de dicho Factory al Semantic Kernel.
Lo que queda ahora es poder utilizar esta Función Nativa y manipular el string que retorna para devolver algo más significativo.
Llamando a nuestra Función Nativa para usar el LLM
Para probar nuestra integración, vamos a crear un Controller con una acción para exponer desde un API REST un endpoint para consumir nuestro LLM.
Y no sólo eso, sino que también nos permita interpretar el resultado para saber a partir del score si vale la pena retornar la respuesta, o mejor contestar un “no sé”.
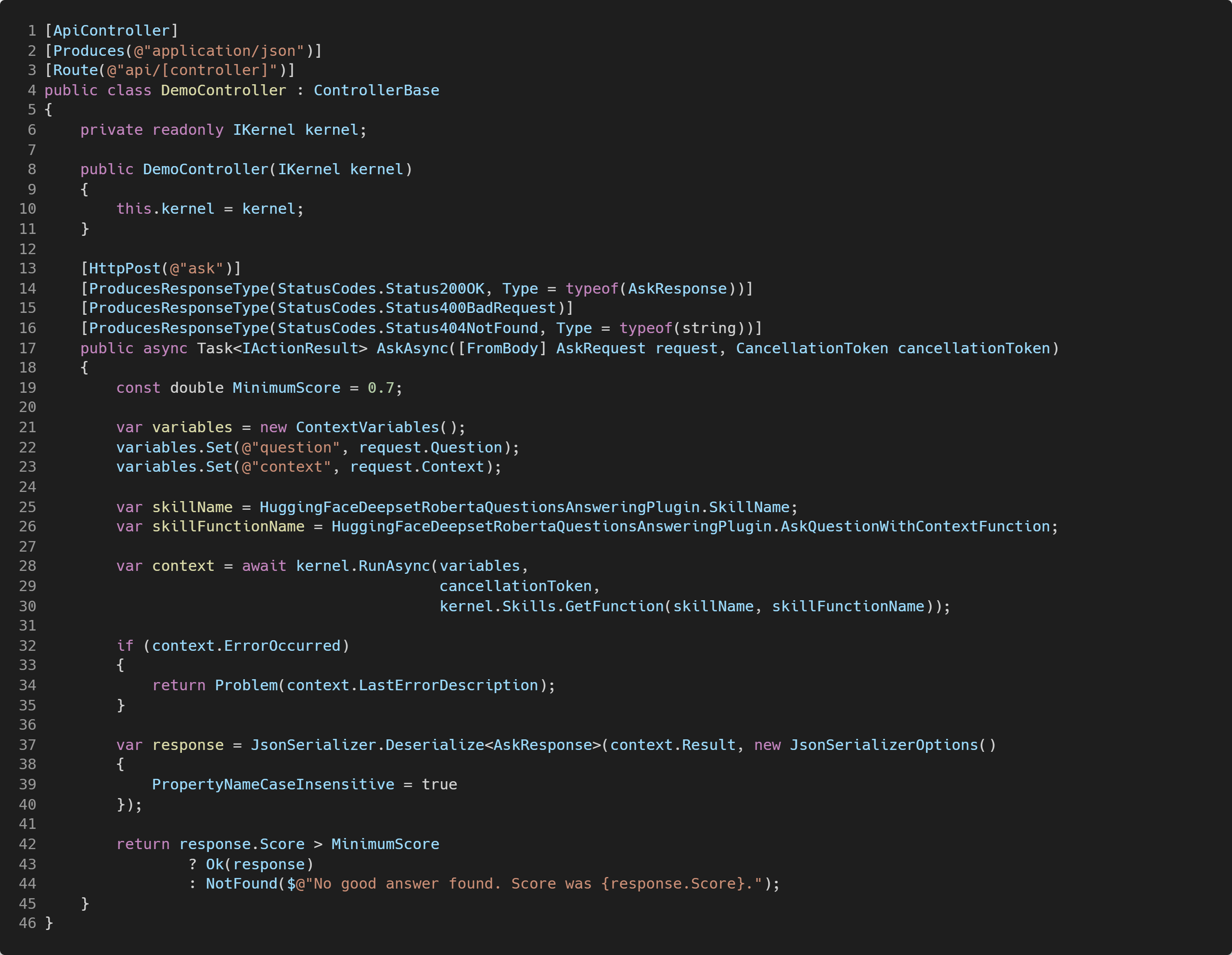
Para esta demo, estoy estableciendo el valor mínimo del score de la respuesta en un 0.7 (un 70% de confiabilidad) para considerarla como válida. Lo idea es que este valor esté parametrizado en una clase de opciones parecida a la que vimos como ejemplo antes con el caso de HuggingFaceOptions. De momento, nos vale con tenerlo como una constante dentro de la acción.
Tomaremos la pregunta y el contexto que nos llegarán por request (clase AskRequest) y sus valores los usaremos en una instancia de la clase ContextVariables que pasaremos como parámetros al Semantic Kernel (representado por una instancia válida del tipo de interface IKernel que recibimos como dependencia en el constructor del controlador).
Para llamar a nuestra Función Nativa registrada en el Semantic Kernel simplemente tenemos que suministrar el nombre de la skill y de la función (líneas 25 a 30). El resultado de la ejecución de la función es una instancia del tipo SKContext, la cual nos ofrece variada información sobre el resultado de dicha ejecución.
Así, con el resultado obtenido, primero verificamos que no haya ocurrido ningún error (excepción), y en caso de haberlo, retornar el mensaje del error correspondiente (líneas 32 a 35).
Si todo ha ido bien, tomamos la respuesta que nos ha llegado como tipo string y que sabemos de la implementación que realmente es un JSON con la respuesta del modelo «roberta-base-squad2». Para obtener los valores de la respuesta, he creado la clase AskResponse que mapea “1 a 1” con algunos de los valores del JSON retornado por «roberta-base-squad2»; y de los cuales nos interesan dos en concreto: la respuesta y su score. Usando el JsonSerializer podemos obtener la instancia de AskResponse con los valores que nos interesan.
Finalmente, verificamos si el score recibido es mayor al valor mínimo que hemos establecido. De ser así, retornamos la respuesta, sino retornamos un HTTP 404 Not Found con un mensaje indicando que no se consiguió una respuesta satisfactoria porque el score era bajo.
Para probar esto, os dejo una colección de Postman con esta llamada y que está disponible en el repo en GitHub mencionado al principio del artículo. Abajo tienes dos imágenes de una respuesta correcta y otra de “no sé” 👇🏻
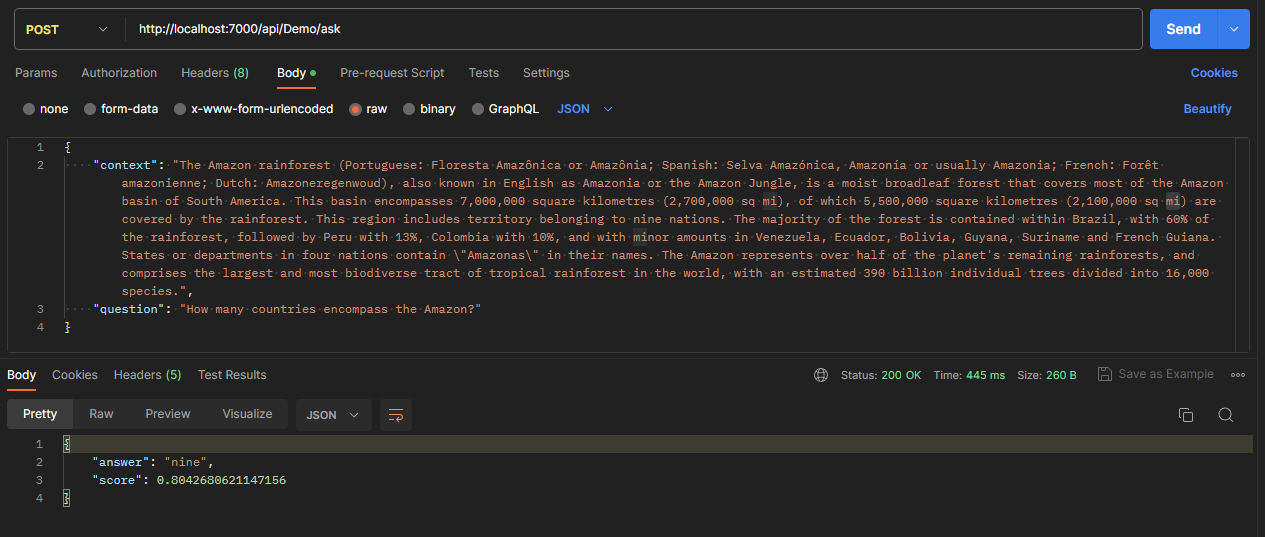
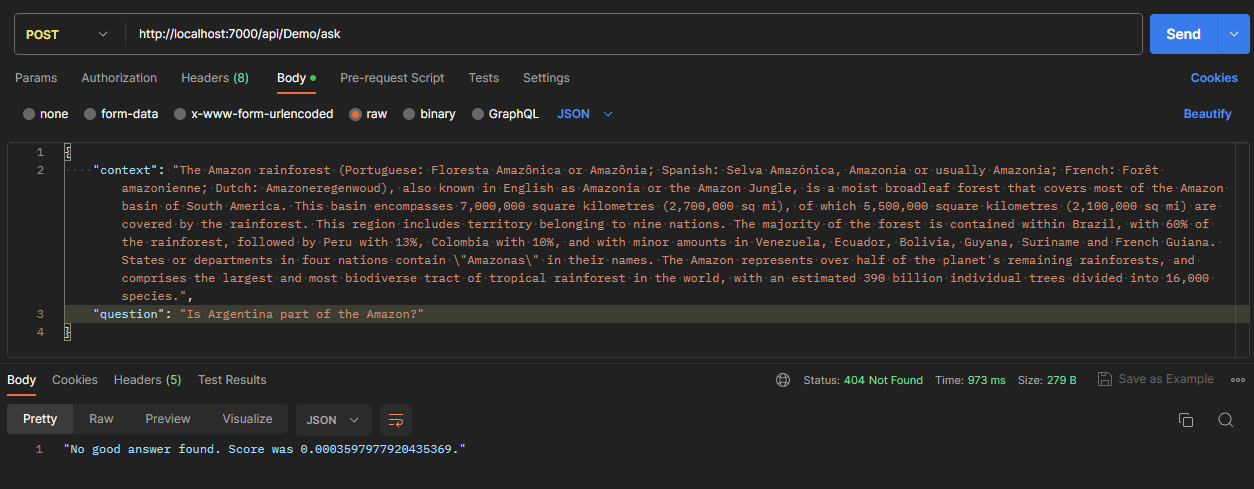
Más información
Si tienes más curiosidad sobre Semantic Kernel, te dejo aquí algunas publicaciones de mi YouTube donde justamente trato sobre estos temas:
- Configuración paso a paso del Semantic Kernel 👉🏻 https://youtu.be/a8gNdF0D23g
- Las Funciones Semánticas en Semantic Kernel 👉🏻 https://youtu.be/jc6H8gmXAAA
- Las Funciones Nativas en Semantic Kernel 👉🏻 https://youtu.be/mSJa0oaS_XE
Si quieres saber más… ¡COMENTA!